

Fictohedron: Writing Team Novels with the Help of a Spam Filter #
You feed a pile of books through a spam filter. Half are books you favor. The other half you pointedly dislike. What words and themes would rise? Obviously crossbows. But perhaps toast?
See, this is what is happening with Fictohedron. I feed ten fictional blogs into the filter. (Francis Hwang’s Ten-Sided project, for which I write as well.) And twenty real blogs. Some of the blogs are mainstream stuff (Gawker, Dooce) but most are just plain LiveJournals. Then, we watch the terms peculiar to Ten-Sided float to the top. I take weekly samples, to be sure new terms rise and timely popular terms get weeded out.
Hooking Up the Filter
I am using bogofilter. And a very short Camping. I fill up two directories ham and spam with blog entries disguised as mail. Then…
bogofilter -s -B spam/* -d bogo
bogofilter -n -B ham/* -d bogo
bogoutil -d bogo/wordlist.db | awk '{print $1}' |
bogoutil -p bogo/wordlist.db > scores
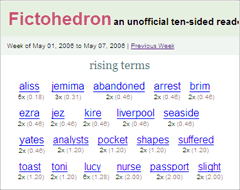
The scores file now contains a list of all the words found and their rating. Low ratings are good, they indicate hamliness. In fact, the stats you see next to each word on Fictohedron is the number of total mentions and, in parens, the filter’s rating.
Terms are only stored in the database if they occur more than once and have a rating less than 25. There’s enough data to show trends and overall ratings. But I don’t want to make it too busy yet, maybe in two more months when Ten-Sided ends.
And This Assists Readers or Writers?
Without the tool, it’s tough for casual readers to sense the common themes between blog entries. You really have to spend time reading each blog, getting to know each character, figuring out how they relate to each other. But the whole point of team writing is to watch the interplay. Wait, which characters ended up in Vegas this week? Who’s seen Aliss and who’s looking for her?
Oh, hey, the word seaside was mentioned twice this week. Look, Toni’s staying at The Golden Chain, a seaside residence. And A.P.’s off to a week-long conference on the seaside. An obvious link. But other connections are more subtle: toast, nurse, pocket. What are people putting in/taking out of their pockets this week?
But I think the tool is even more beneficial to the writers. How do you leave clues for the others without using marquee tags?
- If a word is dominating and you can fit it into your story, do it. But twist it, contrarywise.
- Mid-week, grab a new word at the bottom of the list and really push it up. Surges like that avoid remaining topically flatlined.
- Drop a word twice within a week and it’ll likely show up. Use these sparingly or you’ll wash out the natural instincts of the filter.
The best part is that not all terms will get picked up. The spam classifier may find the terms too droll given the state of the corpus. Which means you either push it harder or wind the plot elsewhere.
Collaborating with Bots, etc.
So, what else could be done? We have the underpinnings for seeding some AI here. Or we could use the filter to seek out new writers from the Net at large. It adds a new dynamic to group writing, doesn’t it?
A few things I’d like to see:
- Bots which could act as incidental characters in the story, set up new blogs, seek out likeminded kids on LJ/MySpace and coexist with them. Thus tying the fiction to the physical world.
- A spider which could continually filter in new bodies of text from published books or Guttenberg, queueing the writers with possible choices of obscure references and footnotes.
- Allow readers to easily rate the terms. The writers can then appease the readers by fueling the preferred terms. Or piss off the readers by bring hated terms to prominence.
It seems like a big goal is to eliminate neutrality in the writing. If the readers don’t care and none of the other writers care, then there’s got to be a way to help it die.
And, I mean, is the story any good? Can we measure that?
Peter Fitzgibbons
HI Why
I get what your’e doing here, but i don’t grok how ten-sided is feeding the filter?
And i also don’t get how this is releated to team-writing? Do you mean a team of co-workers all blogging their experience? Or do you mean a team of fictionalists threading together a quilt of fantasy?
Love your stuff nevertheless! Always interesting how you weave and bob within the bouncy space-time fabric that is our rouge gem.
Manfred
For my master thesis I tried to find ‘conversation partners’ based on documents I had of a large number of people. I used Probabilistic Latent Semantic Analysis to find out if two people were writing about roughly the same material.
That sort of worked.
why
Peter: Hey, Peter. Ten-Sided is a team of ten writers, each with a fictional blog. Francis talks about it here.
Fictohedron is something I wrote. It grabs feeds for these blogs and feeds it into the filter. I know this is a lot to drop on you!
Manfred: LSI is fantastic. I wish there were more tools and less papers. Your paper withstanding.
FlashHater
Do EigenCharges play into this?
Danno
Here’s this post: x
Here’s my head: O
Manfred
I could write a small library for Ruby… I need a new project to work on in the park with all this nice spring weather.
hgs
Manfred: Please do create such a library. I suspect it would have wider application, to signals other than text. Also, it would facilitate “finding similar documents”, I think. Anyway, being able to handle text at an abstraction higher than “regexp” would be good.
nil
i can’t wait to datamine my own head, then adjust to the results to ensure i keep myself intresting. to much toast is boring.
MenTaLguY
toast. toast. toast. toast. toast. toast. toast. toast. toast. toast. toast. meow. toast. toast. toast. toast. toast.
Comments are closed for this entry.